Why Build This? 🔗
Cloud Service Providers like AWS have serverless databases like DynamoDB and RDS. The only issue is that DynamoDB is a nosql database and RDS requires you to pick out instance types unless you want to use Aurora. RDS can also add up in costs fast if you provision large instance types for your cluster. It would be nice if there was a pay as you go type of model like how AWS Lambda works. If its not being used, you do not pay anything even if you have lambda functions in your account.
The Solution 🔗
Relational databases work by taking queries in as an input and running them against the data it has stored. The database then returns the resulting data to the requester. The solution is to use S3 for the data storage and to use Lambda as the part that runs queries on the data. The AWS Lambda function will pull the data down from S3, then run the requested query against the data and lastly return the result to the requester. This is an oversimplification since there are a few other problems that need to be solved. One is that some queries involve write operations. If you run a query that performs a write operation in the database the changes will need to get saved into S3. But if two queries are running at the same time, you can run into synchronization issues. Below is a diagram of the solution.
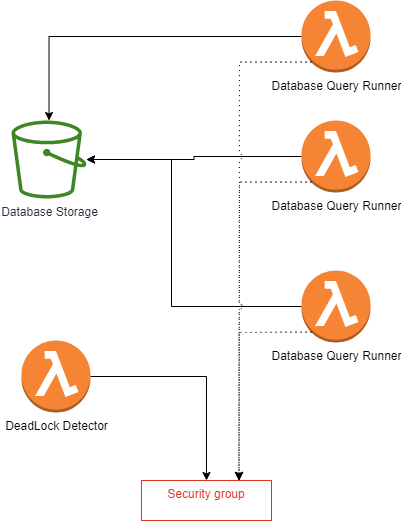
The solution shown above supports multiple queries getting run against the same database at the same time. The solution to the synchronization issue it to use a lock. I found creating an AWS Security Group is an atomic operation. So I am using creating/deleting of a specific AWS Security Group as acquiring/release a lock. The Database Query Runner’s shown above are instances of one lambda function that runs the queries. The first thing it does is check if the query is a read only query or not. If it is a read only query it can safely download a copy of the database as is. If it gets modified in the middle it will keep downloading the version it was downloading. If the operation will modify the database, it will first need to acquire the lock. It does this by creating a specific Security Group with a specific name. The names of Security Groups have to be unique in a VPC. If it creates the Security Group, it makes note of the Security Group ID. It then downloads a copy of the database and runs its query against the data. When its done running the query it releases the lock by deleting the security group.
Weird things can happen in the real world and a write operation might have caused the lambda to get a lock but it might have crashed part way through the query operation so the lock will not get released. To fix this possible issue there is a second lambda function that checks for this case. It does this by keeping track of how long the Security Group has existed and if its been around too long it deletes it. This frees the lock.
Below is a code snippet that acquires a lock. The lock is the AWS security group id.
def acquireLock():
print("Acquiring Lock...")
while True:
try:
resp = client.create_security_group(Description="DistributedLockTest", GroupName="DistributedLockTest", VpcId=vpc_id, TagSpecifications=[{"ResourceType": "security-group","Tags": [{"Key": "CreateTime","Value": str(time.time())}]}])
if resp["ResponseMetadata"]["HTTPStatusCode"] == 200:
return resp["GroupId"]
except:
print("Failed to acquire lock. Backing off and trying again...")
time.sleep(1)
Below is a code snippet that releases the lock aquired in the function above.
def releaseLock(lock):
print("Releasing Lock...")
while True:
try:
client.delete_security_group(GroupId=lock)
return None
except:
print("Failed to release lock. Trying again...")
time.sleep(1)
The source code for the proof of concept can be found here: https://github.com/Craigspaz/AWSServerlessDB
Note: This was created for experimental purposes and should not be used in a production environment